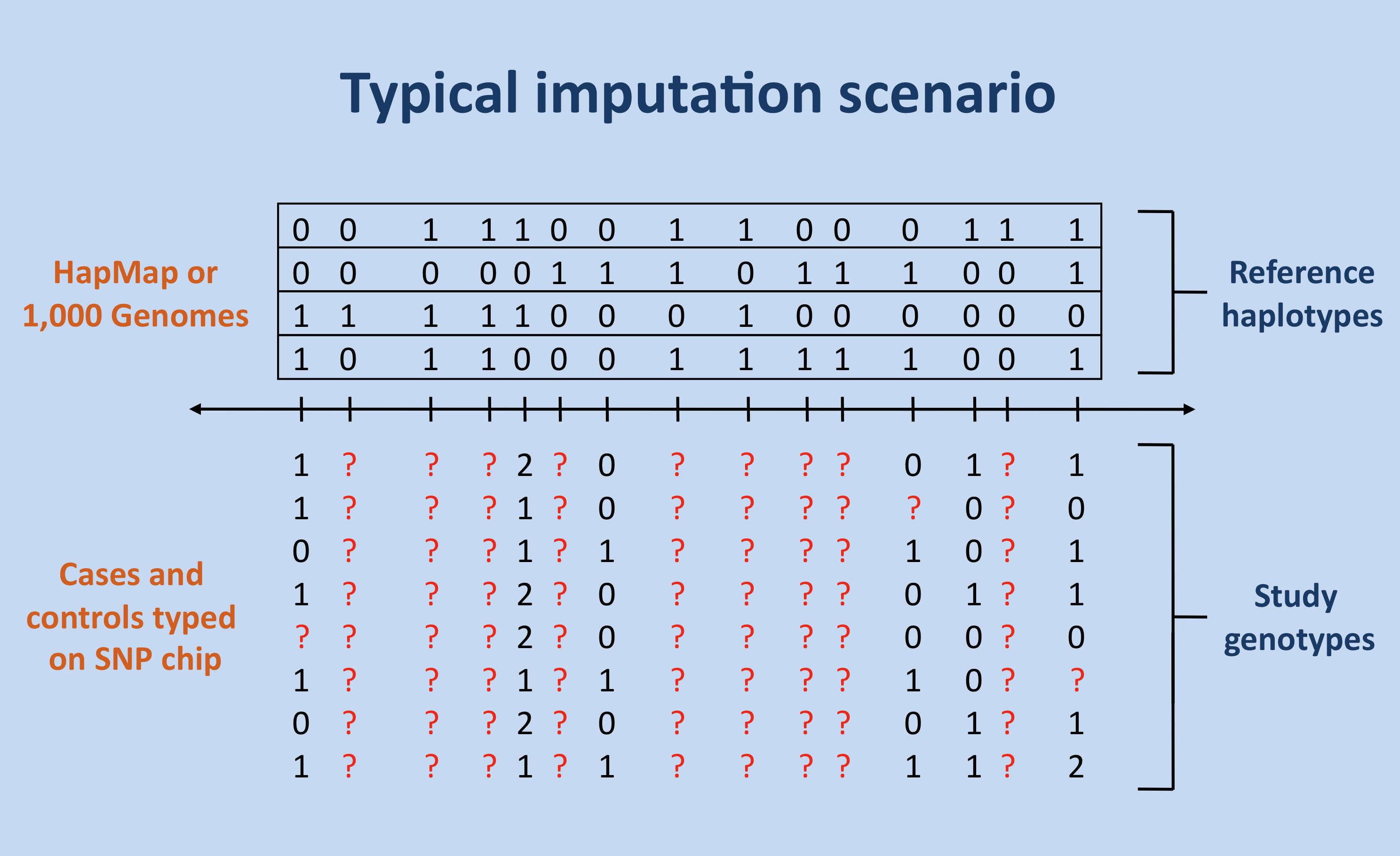
Currently, with large scale human genomic sequencing, a wealth of information has become available for use in genetic analysis like GWAS, or inferring demographic histories of populations. However, the quality of this information varies across different reference databases. Also, population specific databases are being generated to be able to obtain more specific information for these studies. Generation of these reference databases is important for performing analysis. In addition, assessing these databases for quality is important to understand which applications a particular dataset can be used for, and the corresponding reliablity of any analysis carried out in this manner.
I worked on the generation and analysis of such databases, in collaboration with various experimental groups in academia and industry. In particular, my work was focussed on the the public 1000 Genomes database, as well as the GenomeAsia 100K Consortium, which is a project to sequence 100,000 Asian individuals to help study of medical questions specific to the Asian population, also from the perspective of addressing demographic questions related to Asian populations.
Publications from this project led and contributed to: